Ollama Model
This section explains how to create, configure, and test an Ollama Model data source in DataDios. Ollama is an open-source tool that allows you to run large language models (LLMs) locally. By configuring Ollama as a data source, you can integrate local AI models into your DataDios workflows.
Prerequisites
Before configuring an Ollama data source, ensure:
- Ollama is installed and running on your local machine or a server accessible from DataDios
- At least one model is pulled (e.g.,
ollama pull mistral:7b-instruct-q4_0) - The Ollama API is accessible via the configured host and port (default:
http://localhost:11434)
Steps to Create and Test an Ollama Data Source
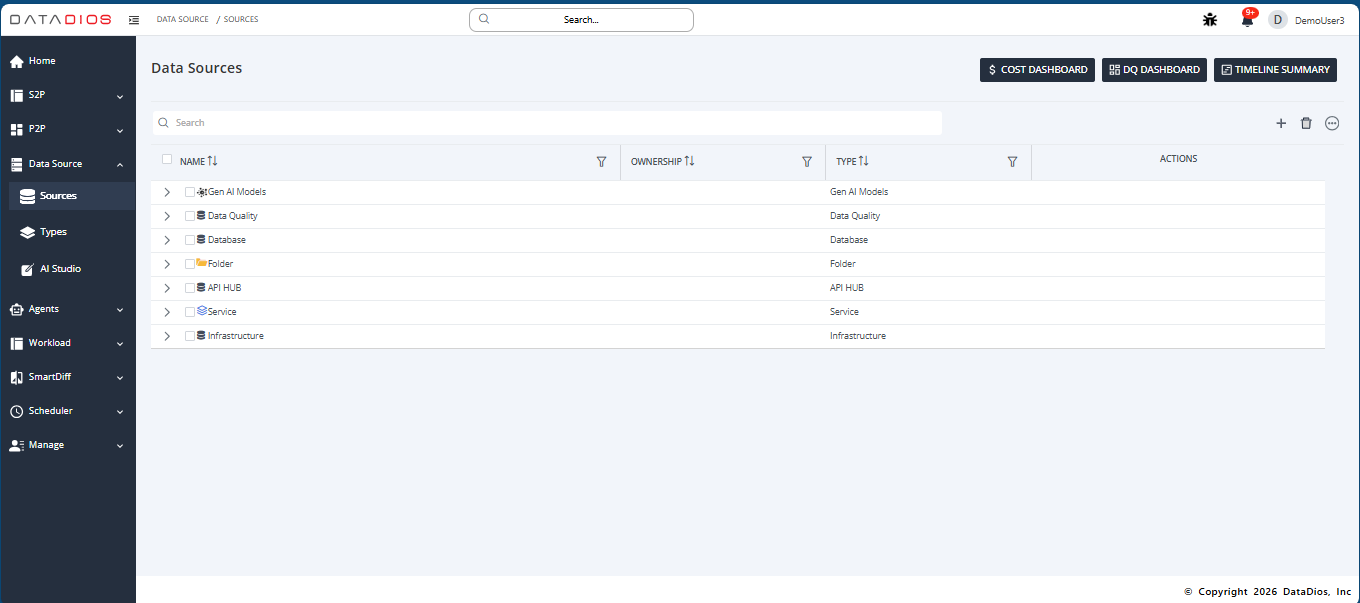
Step 1: Navigate to Data Sources
-
Navigate to the Data Sources tab in DataDios
-
You will see a list of existing data sources organized by type
Step 2: Create a Data Source
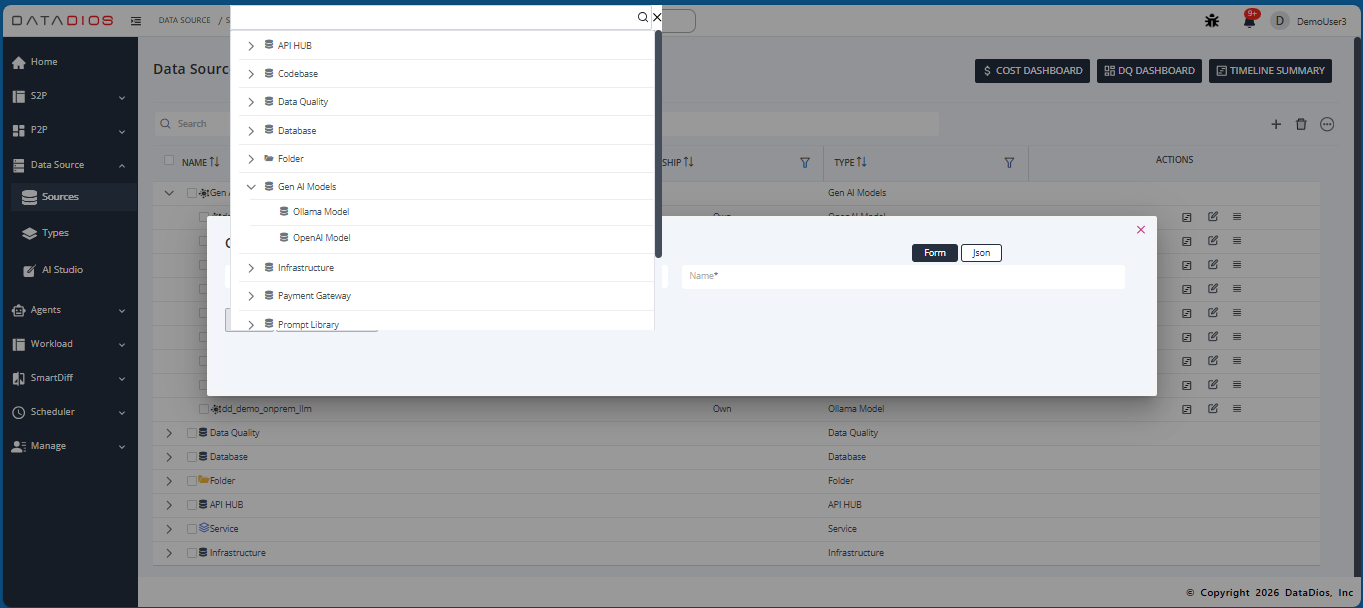
-
Click + CREATE SOURCE (or the + button)
-
In the data source type dropdown, expand Gen AI Models
-
Select Ollama Model
Step 3: Fill Connection Details
In the Create Data Sources form, provide the required parameters:
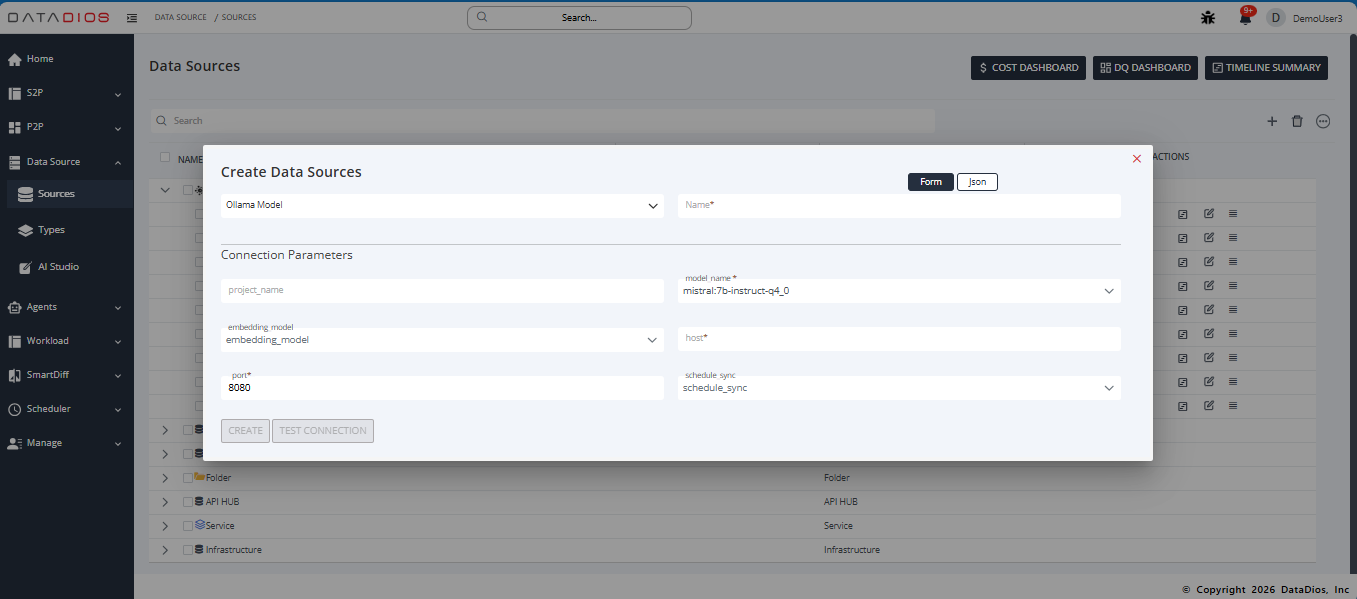
- Name: A unique name for your Ollama data source (e.g.,
QuickStartOllama) - project_name: Project identifier for organizing your models
- model_name: Select the Ollama model to use (e.g.,
mistral:7b-instruct-q4_0) - embedding_model: Select an embedding model for vector operations (e.g.,
mxbai-embed-large) - host: The Ollama server URL (e.g.,
http://localhost:11434or your server IP) - port: The port number where Ollama is running (default:
11434) - schedule_sync: (Optional) Configure for metadata synchronization (see Metadata Timeline)
JSON Configuration
You can also configure the data source using JSON format by clicking the Json toggle:
{
"project_name": "ollam_local",
"model_name": "mistral:7b-instruct-q4_0",
"embedding_model": "mxbai-embed-large",
"host": "http://localhost:11434",
"port": "11434",
"schedule_sync": ""
}
Step 4: Test Connection
- After entering details, click TEST CONNECTION
- Ensure the connection is validated successfully
- If the test fails, verify:
- Ollama service is running (
ollama serve) - The host and port are correct
- The specified model is available (
ollama list)
- Ollama service is running (
Step 5: Save Data Source
- If the test succeeds, click CREATE to save the data source
- You will be redirected to the Data Sources Listing Page, where the Ollama data source will appear under Gen AI Models
Step 6: Update Data Source (Optional)
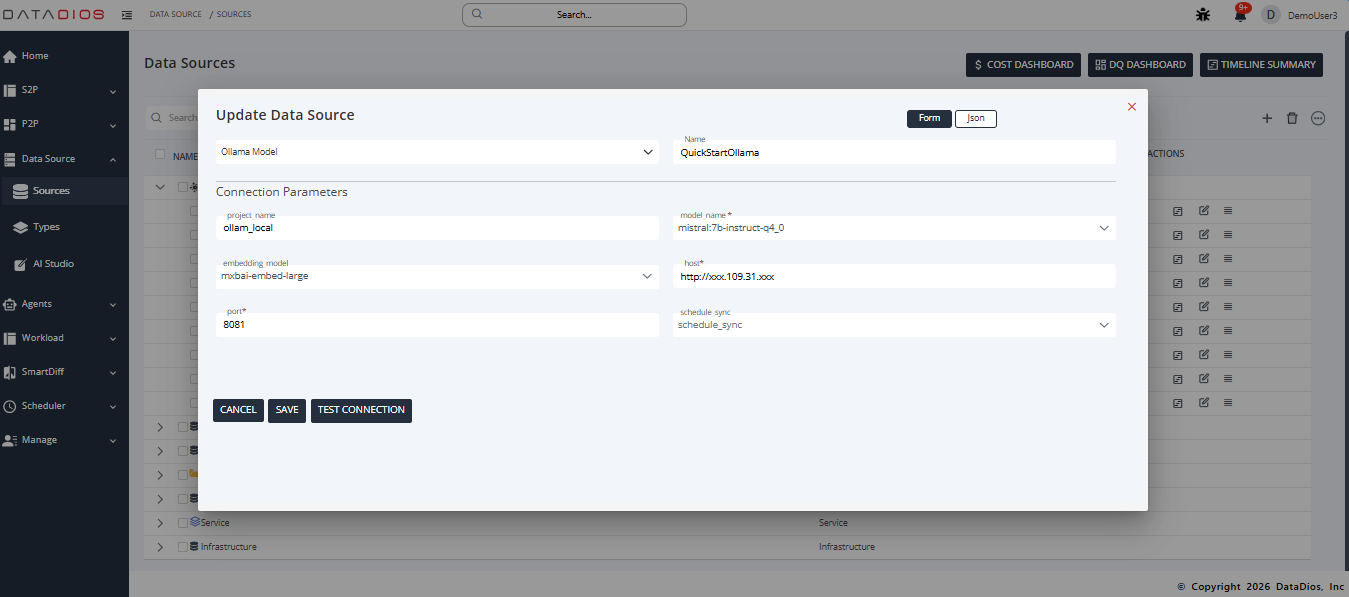
To modify an existing Ollama data source:
-
Click the edit icon (pencil) next to your Ollama data source
-
Update the connection parameters as needed
-
Click TEST CONNECTION to verify the updated configuration
-
Click SAVE to apply changes
Available Ollama Models
Common models you can use with Ollama include:
| Model | Description | Use Case |
|---|---|---|
mistral:7b-instruct-q4_0 | Mistral 7B instruction-tuned | General purpose, chat, coding |
llama2 | Meta's LLaMA 2 | General purpose NLP tasks |
codellama | Code-specialized LLaMA | Code generation and analysis |
llama3 | Meta's LLaMA 3 | Advanced reasoning and chat |
For embedding models:
| Model | Description |
|---|---|
mxbai-embed-large | High-quality text embeddings |
nomic-embed-text | Fast, efficient embeddings |
Using Ollama with AI Studio
Once configured, you can use your Ollama data source in AI Studio for:
- Natural language queries on your data
- Text generation and completion
- Document analysis and summarization
- Code generation assistance
For detailed information, refer to the AI Studio documentation.
Best Practices
- Use Local Network for better performance when running Ollama on a local server
- Choose Appropriate Models based on your hardware capabilities (smaller quantized models for limited resources)
- Test Connection before saving to ensure the Ollama server is accessible
- Monitor Resource Usage as LLMs can be memory-intensive
- Keep Models Updated by periodically pulling the latest versions (
ollama pull <model>)
Troubleshooting
| Issue | Solution |
|---|---|
| Connection refused | Ensure Ollama is running with ollama serve |
| Model not found | Pull the model first: ollama pull <model_name> |
| Timeout errors | Check network connectivity and firewall settings |
| Out of memory | Use a smaller quantized model or increase system RAM |